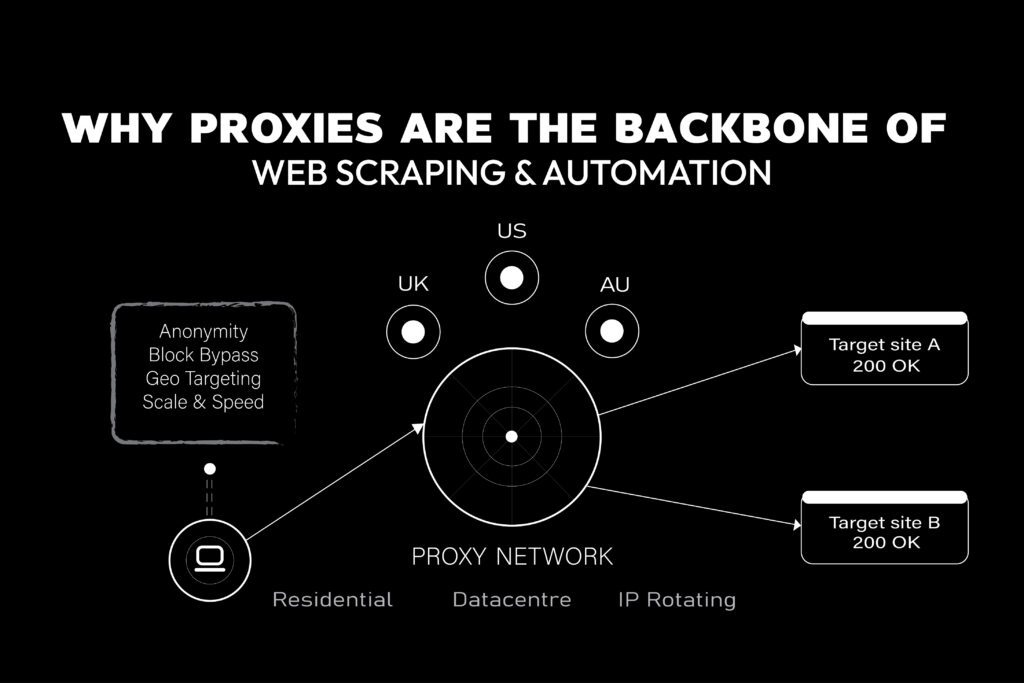
Why Proxies Are the Backbone of Web Scraping & Automation
If you’ve ever tried scraping a website or automating browser tasks at scale, you’ve run into a wall: IP bans, CAPTCHAs, and rate limits. Proxies are the solution. However, not all proxies are alike. Choosing the wrong type can waste money, get you blocked instantly, or deliver slow and unreliable results. This guide breaks down …
Why Proxies Are the Backbone of Web Scraping & Automation Read More »







